Step 1: You need to be done with downloading and installing the Shoviv Cloud Drive Migrator, you can launch and run the software. The utility greets you on the main interface or dashboard.
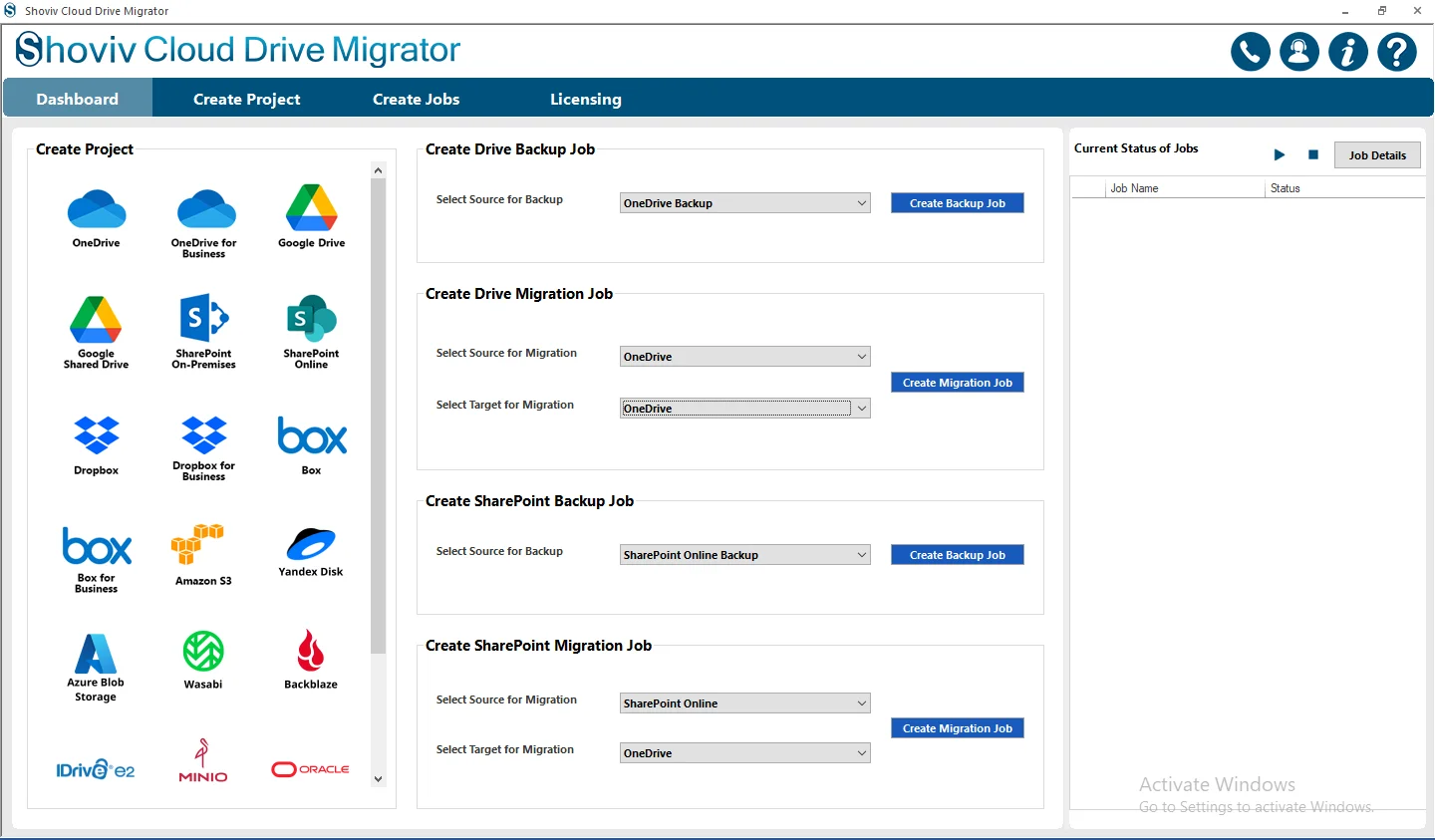
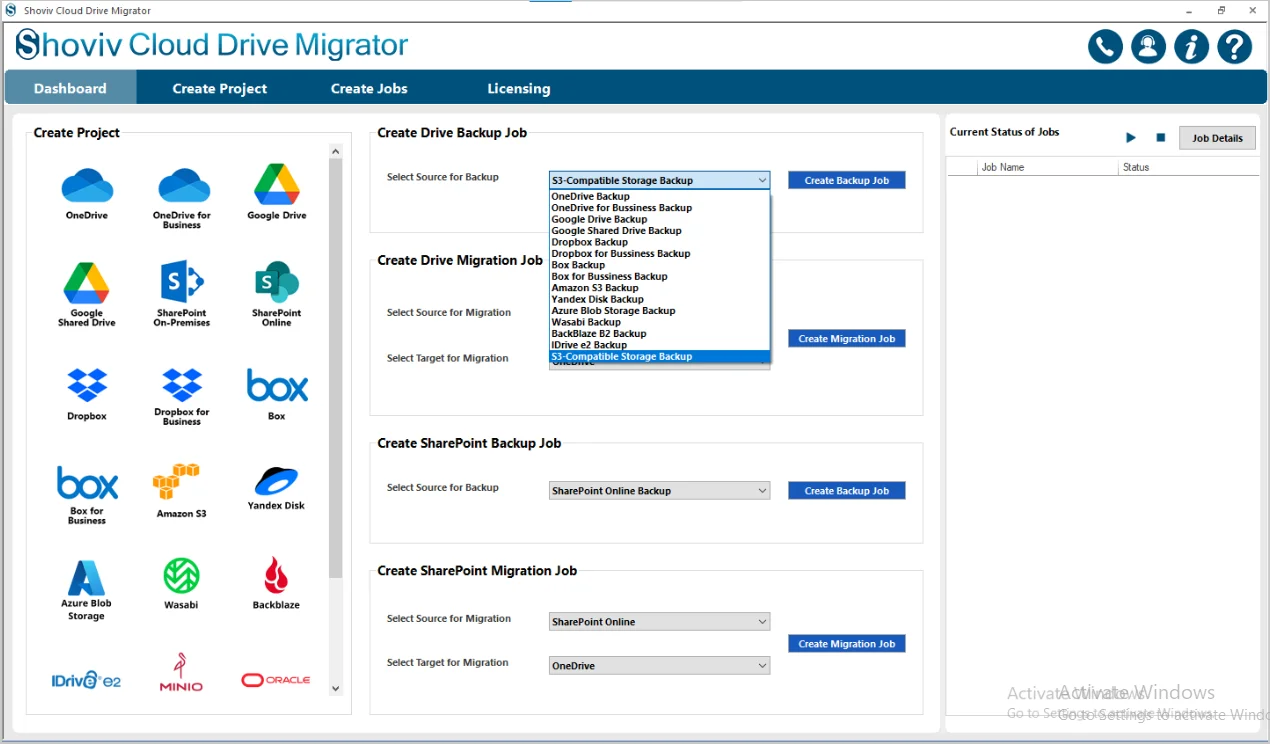
Step 2: From the dashboard, go to the Create Drive Backup Job. In this section, you need to select the source for Backup with the help of the dropdown menu.
- Pick the S3- Compatible Storage as the Source and then click on the Create Backup Job.
Step 3: Type the name of the job in the field of the Job Name.
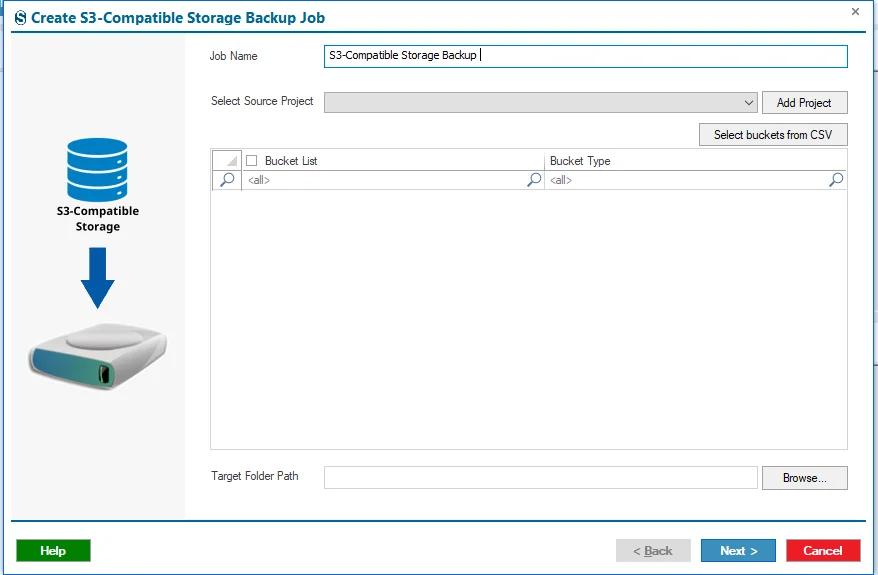
Step 4: Connect with the Source Project by clicking on the Add Project button, and then give the name of the project in the field of the Project Name.
Enter the Access Key, Secret Access Key, and Region Endpoint within the Connection Details according to which S3-Compatible you want to take a backup.
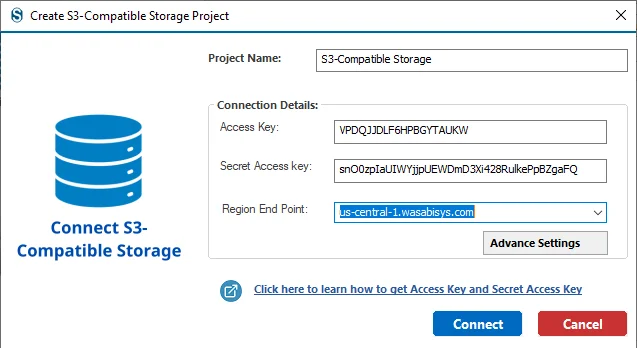
Step 5: Click on the Advanced Settings to adjust according to the bucket present in your S3 -Compatible Storage, Signature Version and Path Style with the help of the dropdown list. Click on the Ok button.
- After entering the Connection Details, click on the Connect button.
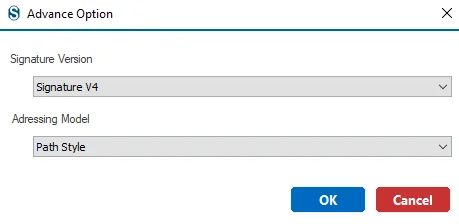
Step 6: Next, select the buckets from the Bucket List and then click on the Finish button after Validate Bucket. In case you have a larger Bucket List for the selection, then you can select the specific bucket with the help of the Select From CSV button.
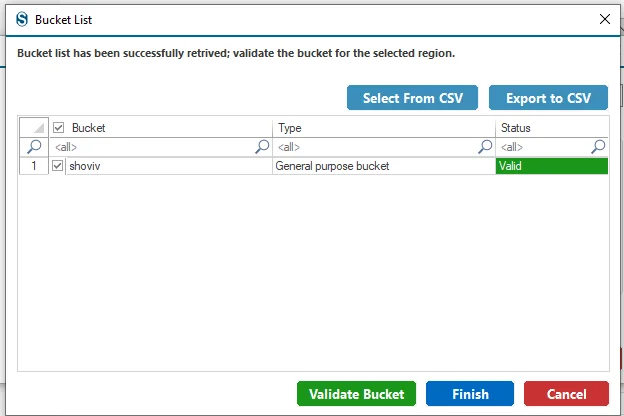
Step 7: Now you will receive the notification about the Project Created Successfully. Click the OK button and proceed.
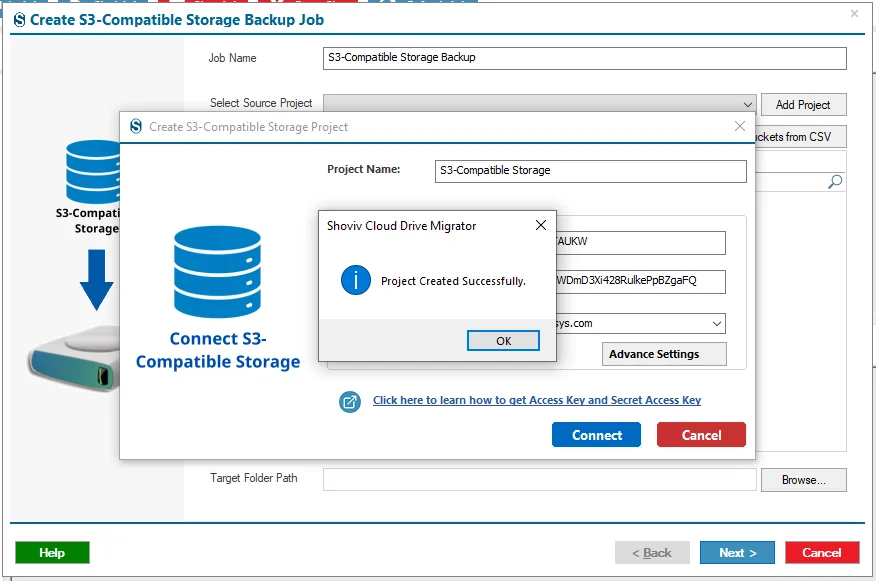
Step 8: Select the Source Project from the list if you already have the project in the system by clicking on the dropdown menu. Next, select the Bucket from the Bucket List.
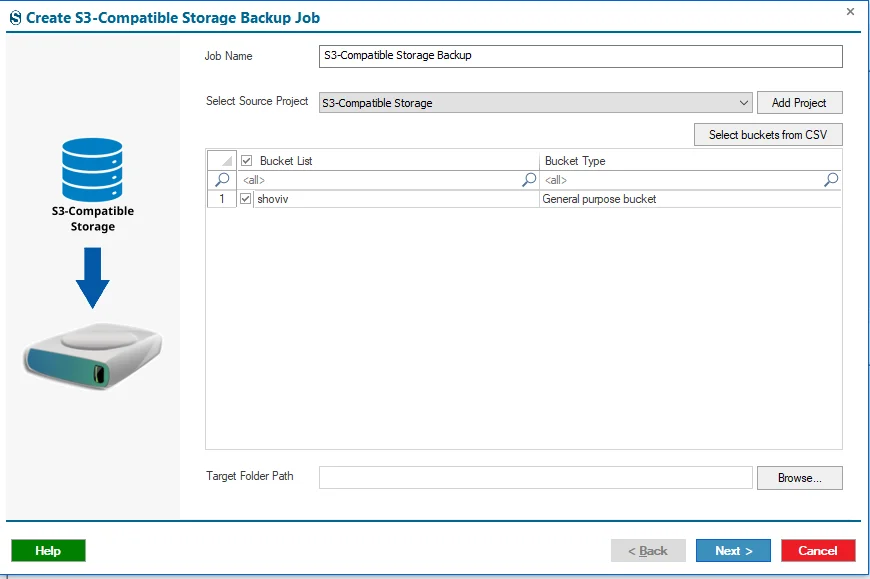
Step 9: If you have the larger list for the selection of the Buckets, then you will select the specific Buckets by clicking on the Select buckets from CSV button.
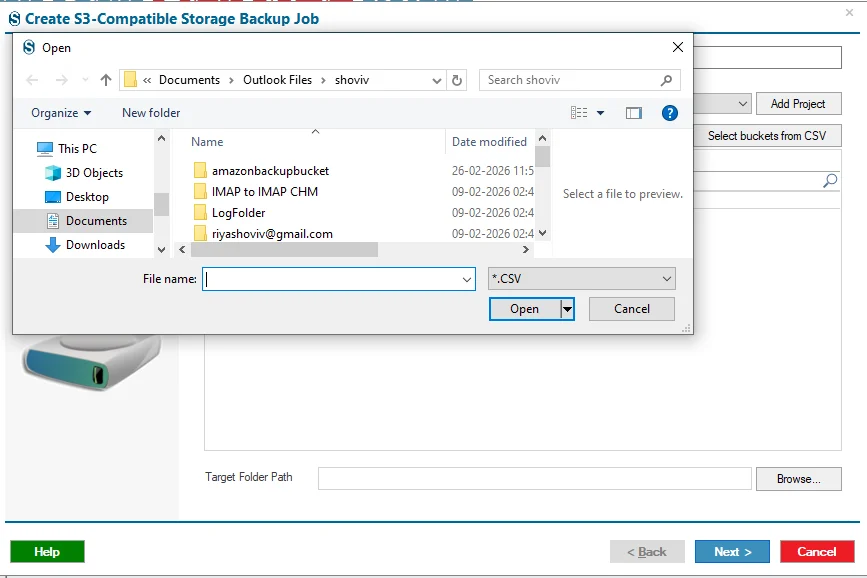
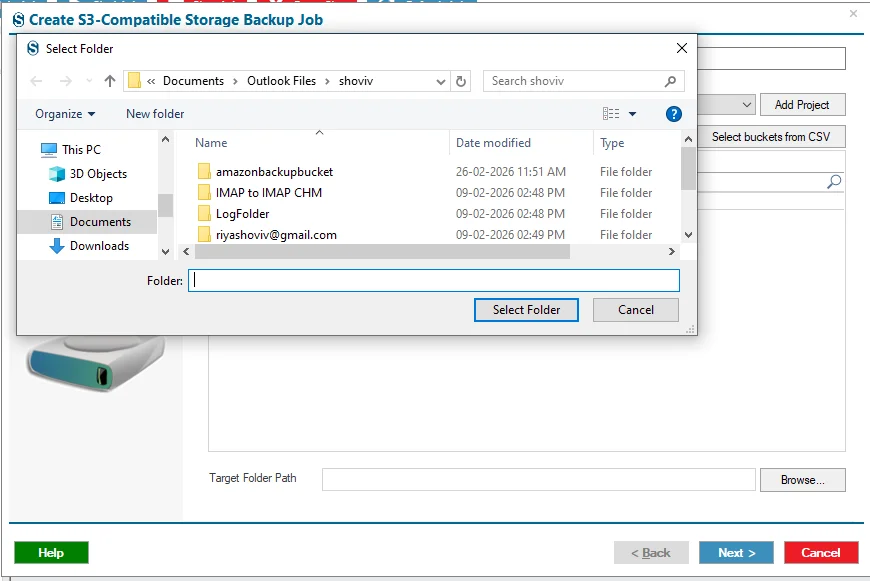
Step 10: Now you need to select the location for the backup of the S3-Compatible Storage by clicking on the Browse button within the Target Folder Path.
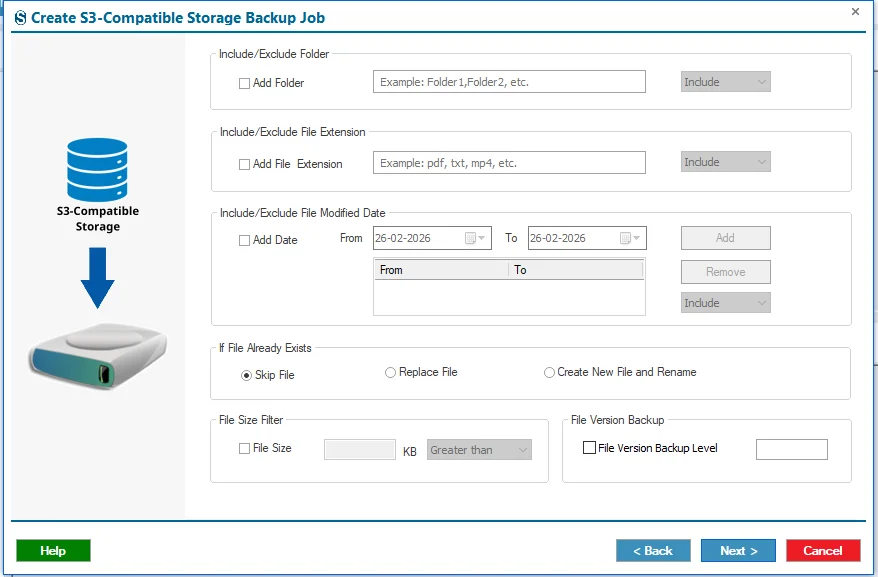
Step 11: Next, you will navigate to the Filters page, where you will find most of the user-centric filter options, such as Folder Filter, File Extension, Date Filter, If File Already Exists, File Size Filter, and File Version Backup Level. These options are explained in detail in the section below.
- Folder Filter: By clicking this option, you can skip a specific folder from the user’s buckets. If you want to back up only certain folders, you can switch to the Include option instead of Exclude.
- File Extension Filter: This option allows you to filter files based on their extensions. You can choose extensions such as PDF, TXT, MP4, etc., by selecting the Include or Exclude option.
- Date Filter: As the name suggests, this filter helps you select files based on a specific date range, either by Modification Date or Creation Date. After choosing the desired date range and files, click on the Add button.
- If File Already Exists: This option defines what action should be taken if a file already exists in the target. It provides three additional options to manage the backup process:
- Skip File: Prevents backing up duplicate files.
- Replace File: Replaces the existing file with the new one.
- Create New File & Rename: Creates a new copy of the file in the target location with a modified name each time (for example, Test (1), Test (2), etc.).
- File Version Backup Level: When enabled, this option allows you to back up different versions of files. The versions are processed from the latest to the oldest.
- Click the Next button once you have finished configuring the filter options. If you prefer not to apply any filters, you can also proceed directly by clicking the Next button.
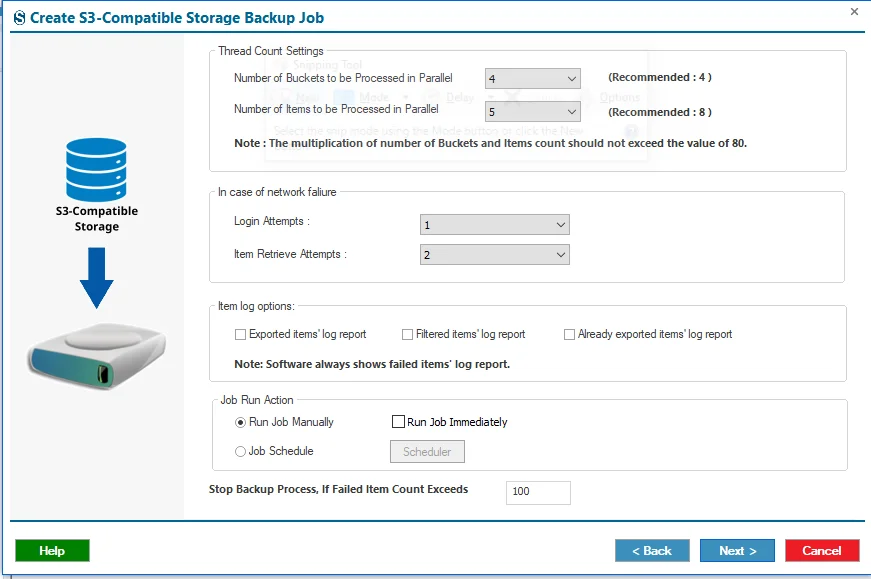
Step 12: Next, you will find the Settings option to refine your backup process further. Here, you will see various configuration options such as Thread Count Settings, In Case of Network Failure, Item Log Options, Job Run Action, and Bad Item Count. These options are explained in detail below:
- Thread Count Settings:-
- Number of Buckets to be Processed in Parallel: This setting controls how many buckets can be processed simultaneously during the backup. For example, if a backup job includes five buckets and the thread count is set to five, the software will back up all five buckets at the same time.
- Number of Items to be Processed in Parallel: This option determines how many threads the software can use within each bucket during the backup. For example, if the thread count is set to ten, the software will process up to ten items at the same time within each bucket.
- In case of network failures:-
- Login Attempts: During the backup process, temporary network interruptions may cause login attempts to fail. This option allows you to define the maximum number of retry attempts before the backup job is marked as failed.
- Item Retrieve Attempts: This setting lets you specify how many times the software should retry retrieving an item from a bucket before marking that item as failed.
- Item log options:-
- Exported items’ log report:- When enabled, the software generates a log report listing all items that have been successfully backed up.
- Filtered Items’ Log Report: This option creates a log report of items that were skipped due to applied filters such as date range, file size, folder selection, or file extension criteria. It helps users understand which items were excluded and why.
- Already Exported Items’ Log Report: By selecting this option, you can open the job report folder containing the log report of items that have already been backed up.
- Note:- The software automatically generates a Failed Items Log Report by default. This report includes details of items that could not be backed up due to errors or other issues, regardless of which log report options are selected.
- Bad Item Count:- This option defines the maximum number of failed items allowed before the software stops backing up a specific bucket. For example, if the bad item count is set to 100, the backup process for that bucket will stop after 100 failed items. You can adjust this value according to your requirements.
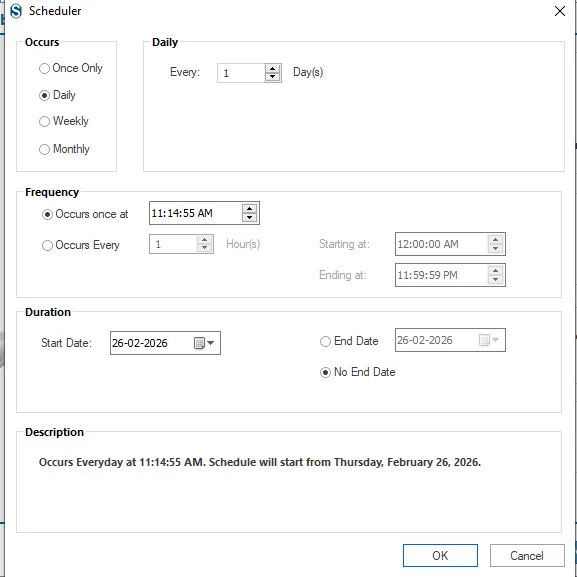
Step 13: The Scheduler plays an important role in the job creation process. It allows users to automate periodic backups by setting a specific start time, ensuring the backup job runs automatically as scheduled.
- Run Job Manually: This option allows you to run the S3-compatible storage backup job at any time directly from the dashboard.
- Run Job Immediately: Choose this option to start the backup job right after completing the job configuration.
- Job Schedule: This option enables you to schedule the backup job for a specific date and time. You can configure it to run once a week or on multiple selected days within a week at a defined time.
- Daily:- Back up buckets every day at a specified time.
- Weekly:- Back up buckets on a weekly basis. You can choose to run the backup once per week or on multiple selected days at a specific time.
- Monthly:- Back up buckets every month or during selected months on specific date(s) as configured.
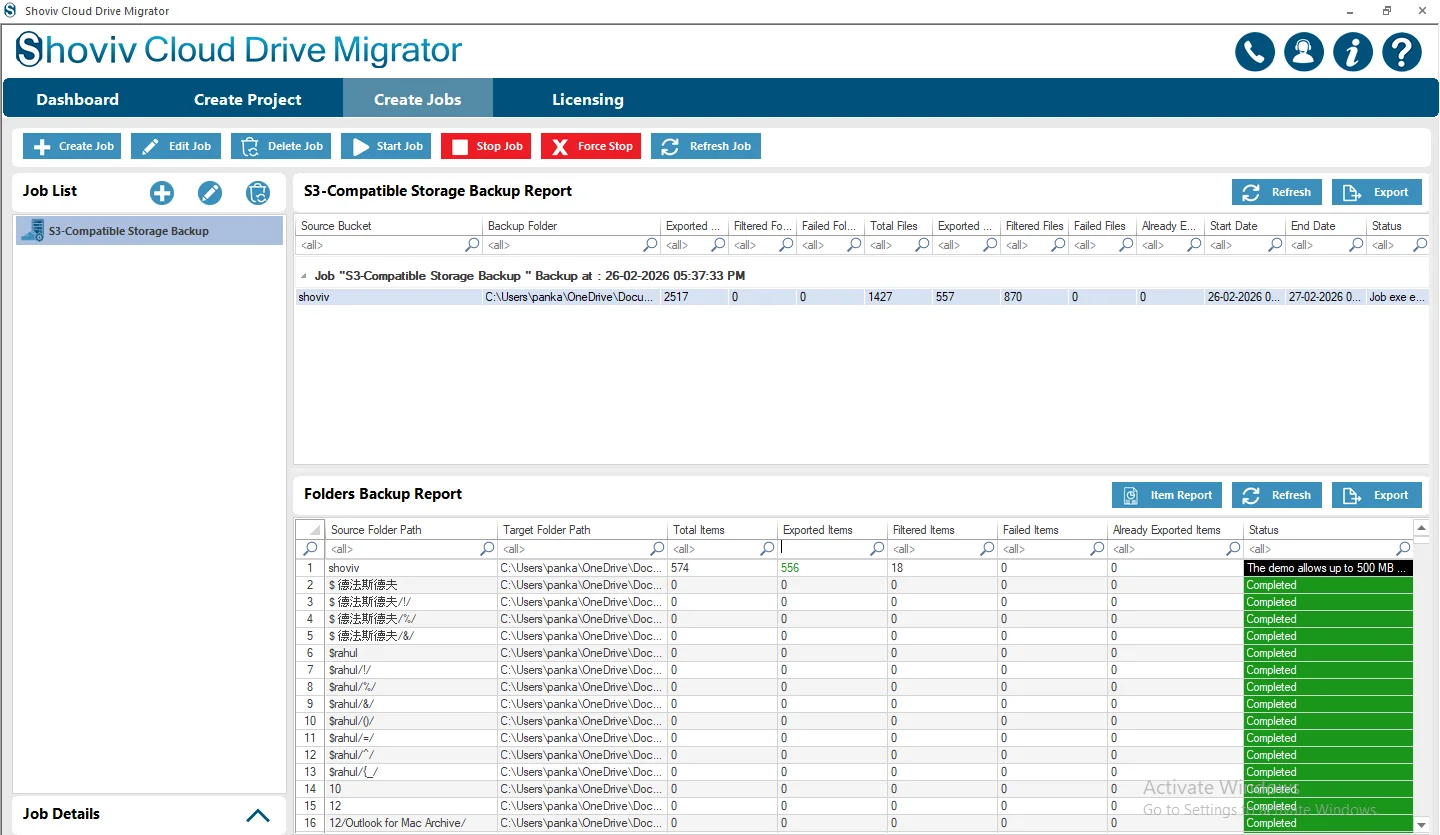
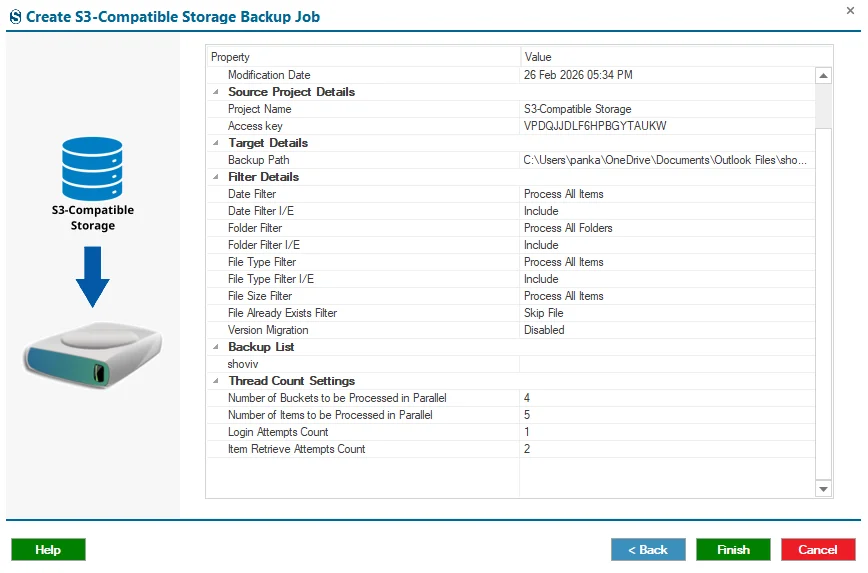
Step 14: Review the job details carefully. If you need to modify any settings, click the Back button to make changes. If everything is correct, click the Finish button to complete the setup.
Step 15: The job will run based on the option you selected. If you chose Run Job Manually, you must click the Start Job button to begin the backup process.